

- JVM结构主要分为四个部分
- 类加载器
- 内存区域
- 执行引擎
- 本地库接口
本地内存,直接内存
本地内存和直接内存都不在jvm中,而是在本地,不受jvm管理.
其中本地内存可以通过本地方法去分配和使用,而直接内存更是特殊,可以直接用java API进行调用,需要手动free,由于没有gc等,适合做大数据的缓冲例如: 网络通信等JVM内存如何划分:
- 程序计数器(记录下一条指令地址)
- 虚拟机栈(栈帧为最小单元,内有局部变量表(基本数据类型和复杂类型的引用),操作数栈,返回地址,动态链接)
- 本地方法栈
- 堆(对象和方法的存储,字符串常量池(jdk7后))
- 元空间(jdk8) (运行时常量池,类的描述信息)
其中前三者为线程私有,每个线程都有各自的. 堆与元空间是线程共享的.
堆的结构划分
新生代和老年代(1:2)
新生代又分为Eden区,survive0,survice1(又叫from和to)from和to不固定,谁空谁就是to
比例为8:1:1
新生代:老年代,以及新生代内部的内存比例都是可配的垃圾回收机制
新生代 复制算法
老年代 标记整理垃圾回收算法的优缺点
标记清除
- 首先通过可达性分析进行标记
- 然后遍历进行清除
优点: 简单粗暴
缺点: 遍历两次效率低,容易出现内存碎片产生内存碎片带来的影响:
当来了一个大对象时,由于全是碎片,导致容纳不下,提前发起gc
标记整理
优点: 不会产生内存碎片,较简单高效,内存使用率高
缺点: 局部变量转移会导致效率变低复制算法
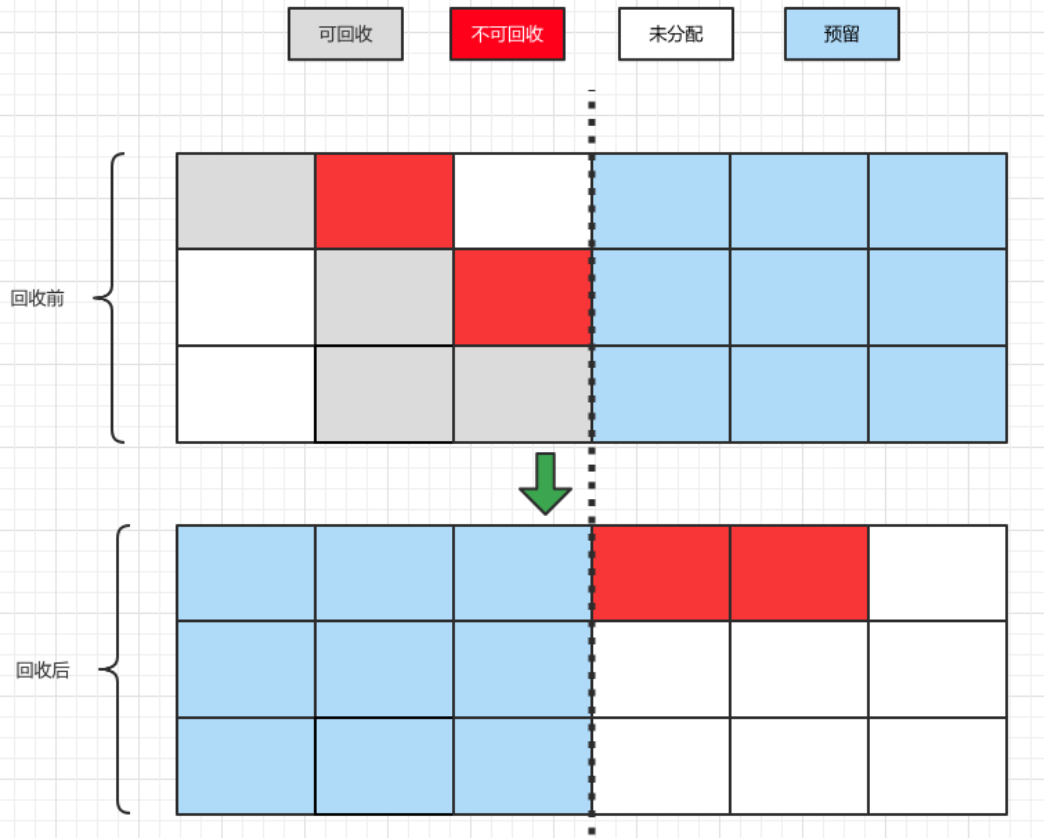
缺点:- 内存使用率低, 需要留下一半空间用于垃圾回收,因此正常存储只能使用不到一半的空间.
- 当存活很多对象时,效率低
优点: 不会产生内存碎片,简单高效
- 如何判断对象是否存活
- 引用计数法
就是为每个对象添加一个计数器,当该对象被引用的时候,就为计数器加一.当对象的引用失效(出作用域)后,计数器减一. 每当对象计数器减为0时,就回收. 当对象被回收时,其引用的对象的计数器减一
缺点: 不能解决对象循环引用的场景, 引用计数器加大了开销
优点: 执行简单,效率高,适合实时环境java程序没有采用引用计数法
- 可达性分析
从GC Roots出发搜索,搜索过的路径为引用链.当对象不能通过引用链与GC root连通时,判定为不可达,可以回收
优点: 可以解决对象循环引用的场景
缺点: 相较而言实现复杂
- 哪些可以做GC roots?
- 虚拟机栈中的引用
- 方法栈中的引用
- 元空间中类静态属性的引用
- 元空间中常量的引用
讲一下hotSpot的垃圾收集器
hotSpot中实现了多种垃圾收集器,并且没有哪个垃圾收集器是最好的,也没有哪个垃圾收集器是万能的.常见的有:- Serial收集器:
单线程gc,同时应用程序需要暂停 - ParNew(Serial的多线程版本)
多线程gc,同时应用程序需要暂停 - Parallel Scavenge
多线程gc,新生代采用标记复制,注重吞吐量(处理用户代码的时间/所有时间) - Parallel Old:
多线程gc,老年代采用标记整理算法 - CMS:
目标: 获得最短回收停顿时间,
采用标记清除算法
第一款可以让回收线程与用户线程基本上同时工作的收集器jdk9中已经被弃用CMS, G1收集器为JDK9后的默认收集器
- G1:
一款面向服务器的,主要针对多处理器,大内存的机器.满足GC时间的同时,还具备高吞吐量的特征
- Serial收集器:
默认的垃圾收集器
jdk8以前:
新生代:Parallel Scavenge 老年代:Parallel Old
jdk9~21: 新生代老年代均采用G1什么时候触发minor gc(young gc)
当eden区剩余空间不足以分配新对象时什么时候触发full gc
当老年代中剩余空间不足以分配新对象时
当老年代剩余空间小于进入老年代的对象的平均大小时CMS的含义:
Concurrent, Mark, Sweepg1较CMS的优点
g1采用标记整理,局部采用复制算法;不会产生内存碎片
g1有时间预测模型,能精准控制回收时间.G1将堆分为多个Region,然后根据控制时间来选择回收收益最多的区域回收(不全堆扫描,增量回收)
g1的清理线程与用户线程不并行,不会产生浮动垃圾G1中的Remembered Set和Card Table
都是用来处理Region中的引用关系.Remembered Set精细化的处理Region间的应用
Card Table粗粒度的处理Region的引用,为Region标记’脏’,回收时优先处理’脏’的Region内存信息排查
- 拿到PID
1
2netstat -ano | findstr ${port} //windows
netstat -ntlp | grep ${port} //linux - jmap -heap ${PID}
- jstack ${PID}
- 应用问题排查,假死排查等
- tcp问题排查
netstat -ntlp | grep ${port}
查看tcp状态是否异常,是否有大量的time_wait - 内存信息排查
内存快照,堆快照,栈快照
cpu过高排查
top找到cpu过高的进程
top -H -p ${pid}找到cpu不正常的线程1
-H: 显示线程
jstack 显示堆栈信息并使用线程号匹配,看是否有异常
对象在内存中是如何存储的(存储布局)
- markword(8字节)
- class pointer(类型指针 4个字节)
- instance data(示例数据 4个字节)
- padding(对齐 总的字节数一定是8字节的整数倍)
- 对象头主要包括什么
markwork和class pointer都属于对象头
markword三大信息:
- 锁信息
- hashcode
- gc信息
- 对象怎么定位
通过对象的引用怎么定位到对象的地址
有两种方式:
句柄方式
引用指向一个实例数据指针
引用指向一个类型数据指针
对象在内存中的位置变化时,引用不需要改变直接指针:
引用直接指向实例数据(实例数据中class pointer指向类型信息)
好处: 快