

redis支持的数据结构: string, list, set, zset, hash, hyperloglog, Geo, Streams
上述是对外数据结构
redis的内部数据结构:
- string的数据结构是:
SDS:simple dynimic string
redis3: - free:未使用空间
- len:字符串的长度
- buffer:一个char类型的数组.空字符结尾,可直接重用一部分c字符串函数
redis6: - alloc: 已分配空间 (alloc-len即为free)
- len:
- buffer:
- flags: unsigned char(): 表示这个字符串的类型(长度类型),从而确定alloc和len的字节数
redis6中还有不对齐内存的机制.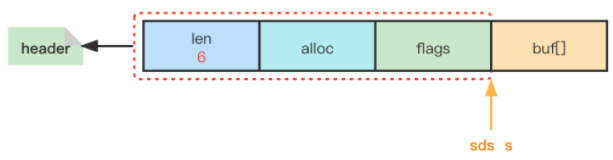
有个细节各位需要知道,即 SDS 的指针并不是指向 SDS 的起始位置(len位置),而是直接指向buf[],使得 SDS 可以直接使用 C 语言string.h库中的某些函数,做到了兼容,十分nice~。
如果不进行对齐填充,那么在获取当前 SDS 的类型时则只需要后退一步即可flagsPointer = ((unsigned char*)s)-1;相反,若进行对齐填充,由于 Padding 的存在,我们在不同的系统中不知道退多少才能获得flags,并且我们也不能将 sds 的指针指向flags,这样就无法兼容 C 语言的函数了,也不知道前进多少才能得到 buf[]。
对比sds和c字符串
常数时间复杂度获得长度
杜绝了缓冲区溢出的可能,当修改时,API回显检查SDS空间是否满足修改所需要求,不满足会自动扩展.
溢出:

两个紧邻字符串,如果这是直接修改Redis为一个更长的字符串,则修改了后一个字符串空间预分配
当需要扩展SDS时,会为SDS分配额外的空间.- 如果修改之后的长度小于1MB,那么程序分配和len一样的未使用空间。比如修改之后的SDS实际长度为13,那么也会分配13字节的未使用空间,SDS的buf数组的实际长度会变成13+13+1=27字节
- 如果修改时候大于1MB,那么程序会额外为SDS分配1MB的未使用空间
惰性空间释放
当字符串缩短时,不着急回收字节,而是通过free属性记录字符串的最大容量是?
512MB为什么最大容量是512MB?
应为len是用int修饰的(redis3),限制了buf最长就是2**31-1list的数据结构:
ziplist(redis3), quicklist(redis3.2), listpack(redis6)listpack的结构:
total-bytes num-element …elements-i… listpack-end-byte(0xFF)- totalbytes占用四个字节,每个listpack最多占用4294967295Bytes.
- num-element占用两个字节.当Entry数大于65535时,如果要获取元素个数,需要遍历listpack
Entry结构
encoding-type element-data element-tot-len注意element-tot-len记录的长度是encoding+data
element-tot-len 所占用的每个字节的第一个 bit 用于标识;0代表结束,1代表尚未结束,每个字节只有7 bit 有效正向查询
先计算 encoding + data 的总长度 len1
通过 len1 可计算出 element-tot-len 的长度
len1 + element-tot-len 之和即为 entry 总长度 total-len
向后移动 total-len 即为下一个列表项的起始位置反向查询
从当前列表项起始位置的指针开始,向左逐个字节解析,得到前一项的 element-tot-len 值,也就可以得到encoding + data的总长度,从而得出entry的总长度;减去entry的总长度,就得到了前一个entry的地址~
hash的内实现
先看看以下命令的输出
1 | hset user name doudou age 18 gender 1 height 175 |
我们会发现输出的结果的顺序与我们放入的顺序完全一致.这绝不是偶然
ziplist->hashtable:
- 当ziplist的zlentry个数大于512时,将从ziplist转为hashtable
可配 hash-max-ziplist-entries 512
- 当单个元素超64mb后,也会转hashtable
可配置: hash-max-ziplist-value 64
set的内实现
dict或者intset(所有数据都使用整数类型表示)
1 | sadd testset 1 2 3 4 7 5 2 |
会输出一个有序的结果
1 | object encoding testset |
- 转hashtable的条件:
- 任意一个成员不能用整数类型表示
- 元素个数超过512
可配置: set-max-intset-entries 512
zset的内实现
zset使用zskiplist(ziplist/skiplist)和dict实现,使用dict记录元素对应的score(即value是score)
当同时满足下列两个条件时,会采用ziplist.否则,采用skiplist
- 元素个数小于128
- 每个元素小于64字节
hashtable是如何解决哈希冲突的
链式哈希.即将拥有相同hash值的数据用链表串起来.
因此,在元素个数远大于数组大小时,会发生严重的hash冲突,链表过长,时间复杂度退化hashtable是如何rehash的
首先一个hashtable中有两个dictht,我们称他们为哈希表1,哈希表2;当非rehash阶段,数据的操作只在哈希表1中进行,然后当触发rehash条件(负载因子大于1且不在进行bgsave和rewriteAof,或者说负载因子大于5)时,就会为哈希表2分配空间(哈希表1大小的两倍),然后渐进式rehash,在我们数据查询,删除,更新时会将对应索引中的元素全部进行rehash到哈希表2,随着操作的次数越来越多,会将所有元素都迁移到哈希表2,哈希表2改为哈希表1,开个空的哈希表2供下次rehash使用.rehash时更新,查询,删除会同时使用哈希表1,2,而新增则直接往哈希表2中新增
redis实现延时队列
使用zset实现,其中score是时间戳
生产者向zset中放入消息和时间戳,消费者请求该zset试图拿数据(score有范围要求延时),如果没有则重试(可以sleep一会释放些cpu资源),有的话则删除
拿数据判断和删除需要是原子操作(lua脚本实现),以防止多个消费者出现异常
优点:
实现简单(对比rabbitmq:需要exchange,queue,binding,routingkey,还要多个queue实现死信队列)
可靠性不如MQ. ack,重传等机制可能都要自己实现
- set的应用场景
- 抽奖
- 点赞
- 共同好友(求交集)
- list的应用场景
消息队列(但是不可靠,不成熟(没ack,重试等机制))